
Top 5 Machine Learning Algorithms
The Complete Beginner's Guide of Machine Learning Algorithms


Machine learning drives the biggest AI breakthroughs we see today - from Tesla's self-driving cars to DeepMind's protein-folding discoveries. These remarkable results have generated significant excitement around the technology. But what is machine learning exactly? How does it work? And does it live up to the hype? This guide explains key machine learning concepts in simple terms, shows real-world applications, and offers starting points for beginners. Whether you're curious about AI's current revolution or thinking about learning these skills, you'll understand what machine learning is and why it matters.
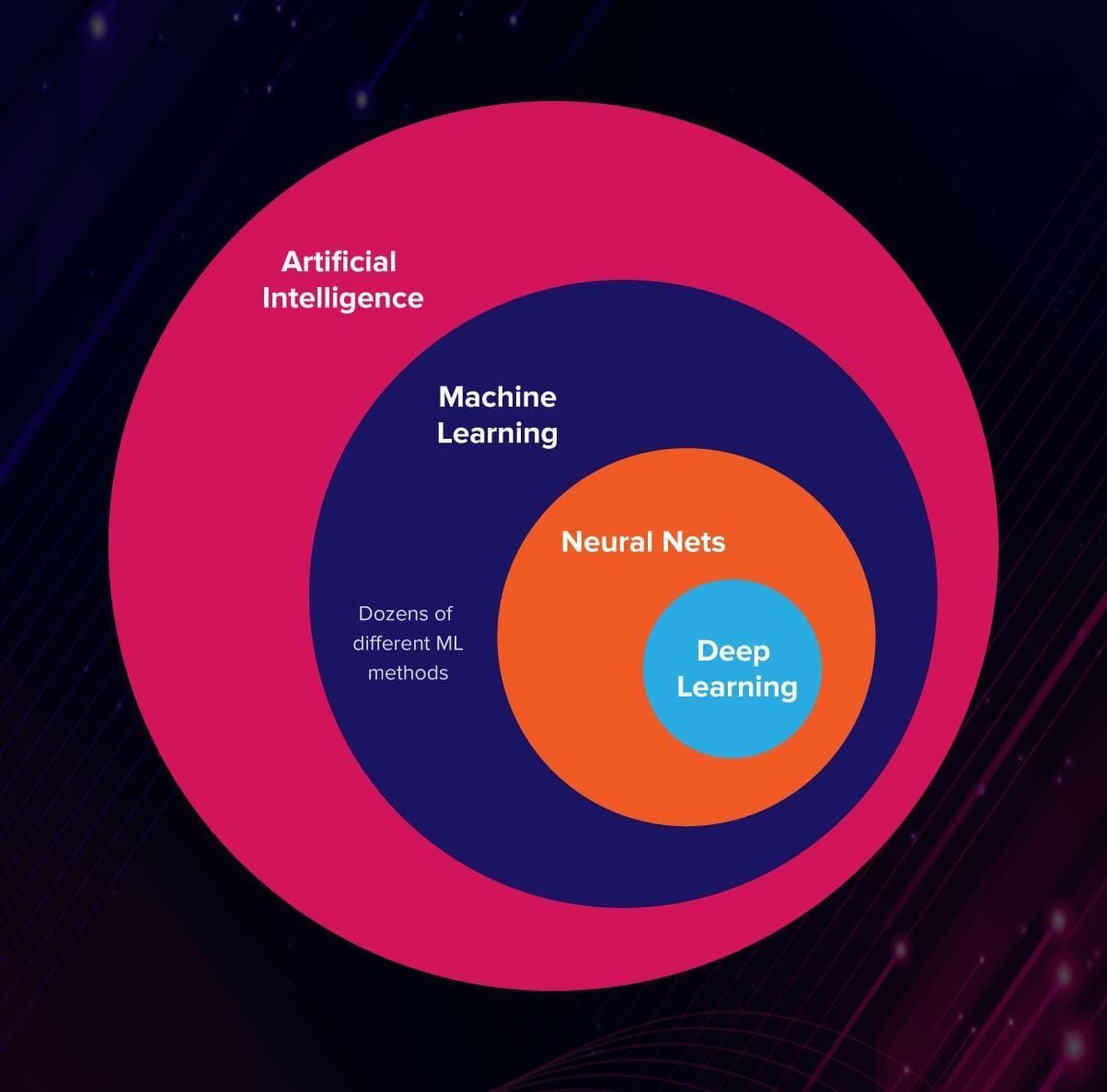
Artificial Intelligence
Andrew Ng, who helped create Google Brain and worked as Baidu's Chief Scientist, gives one of the clearest explanations of artificial intelligence. He describes AI as a "massive toolkit for making computers act smart."
This definition encompasses a remarkably broad range of technologies. On one end, you have basic systems like calculators that follow exact instructions to solve math problems. On the other end, you have sophisticated machine learning programs that can learn to spot spam emails by studying millions of examples.
What makes Ng's definition so useful is that it shows AI isn't just one thing - it's an entire collection of different approaches and techniques. Whether a computer is following pre-written rules or learning patterns from data, if it's solving problems in ways that seem intelligent, it falls under the AI umbrella.
This broad view helps explain why AI appears in so many different forms, from simple automated systems we use every day to complex learning algorithms that can adapt and improve over time.
Machine Learning
Machine learning is a branch of AI where computer programs automatically discover patterns by studying past data. Instead of being told exactly what to do step-by-step, these systems learn on their own and use what they've learned to make predictions about new information.
Think about how traditional computer programs work, like a calculator. Programmers write specific instructions that tell the computer exactly what to do in every situation. This works fine for simple tasks, but it becomes impossible when dealing with complex, constantly changing problems.
Here's a perfect example: fighting email spam. You could try building a spam filter the old-fashioned way by creating rules like "block emails with suspicious subject lines" or "flag messages with certain links." But this approach falls apart quickly because spammers adapt. As soon as they figure out your rules, they simply change their tactics to get around them.
A machine learning approach works completely differently. Instead of writing rigid rules, you feed the system millions of real spam emails. The program analyzes all this data and automatically identifies the common traits that make an email "spammy." Then, when new emails arrive, it compares them against these learned patterns to decide whether they're spam or not.
The key difference? The traditional method breaks down when faced with new situations, while machine learning systems get better at handling change because they've learned underlying patterns rather than just following fixed rules.
Deep Learning
Deep learning is a specialized type of machine learning that handles the most complex AI tasks we see in everyday life. These systems work similarly to how our brains process information and need massive amounts of data to learn effectively. You'll find deep learning powering voice recognition on your phone, language translation apps, self-driving cars, and other "smart" technologies that seem almost human-like in their abilities. What makes deep learning special is its ability to tackle problems that require understanding patterns the way humans do - recognizing speech, understanding language, or making split-second driving decisions.
The Different Types of Machine Learning
Now that you understand what machine learning is and how it connects to other AI concepts, let's explore the main types of machine learning algorithms.
Machine learning breaks down into four main categories: supervised, unsupervised, reinforcement, and self-supervised learning. Each type works differently and solves different kinds of problems. Let's look at how each one works and where you'll typically see them used.
Supervised Machine Learning
Most machine learning works through supervised learning, where algorithms study past examples to make predictions about new situations.
Here's how it works: you show the algorithm both the inputs (the information you have) and the correct outputs (what you want to predict). The system learns the connection between them, then applies this knowledge to new data.
Let's use spam detection as an example. To train a supervised learning system, you'd feed it thousands of emails that are already labeled as "spam" or "not spam."
For each email, the algorithm looks at features like:
Subject line text
Sender's email address
Email content
Suspicious links
Other clues that might indicate spam
By studying these labeled examples, the system learns which combinations of features typically mean "spam." Then, when a new email arrives, it can analyze the same features and predict whether it's spam or not.
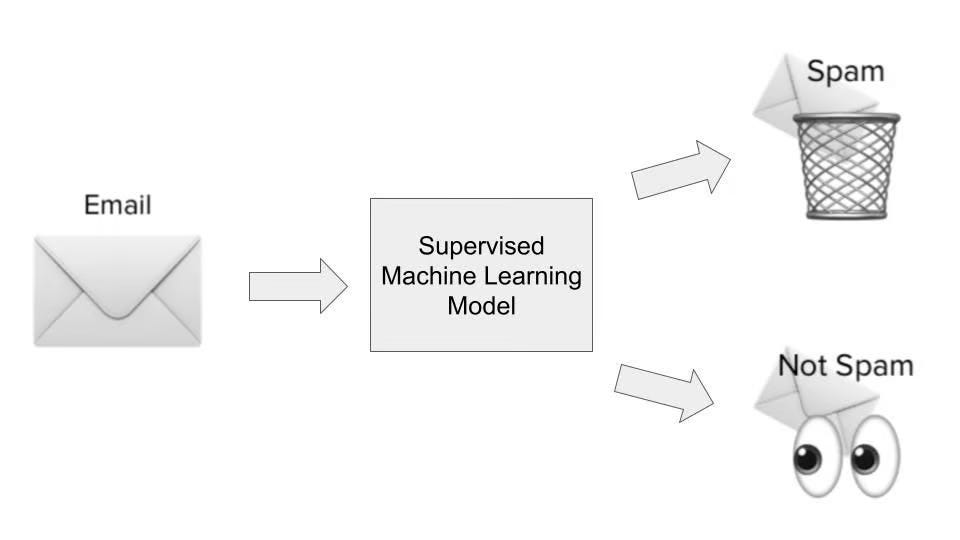
The output is simply "spam" or "not spam." The algorithm studies thousands of these examples and figures out which email features usually lead to which outcome. Once trained, it uses this knowledge to classify new emails it's never seen before.
Supervised learning handles two main types of problems:
Regression predicts numbers within a range. Think house prices - the algorithm considers square footage, location, bedrooms, and other factors to predict a specific dollar amount.
Classification sorts things into categories. Our spam detector is a classification (spam vs. not spam). Other examples include predicting if customers will cancel their subscriptions or identifying objects in photos.
The key difference? Regression gives you a number, classification gives you a category.
Unsupervised Machine Learning
Unsupervised learning works differently - it finds hidden patterns in data without being told what to look for. Instead of learning from examples with correct answers, these algorithms explore data and discover groupings on their own.
Customer segmentation is a perfect example. Companies know they have different types of customers, but want data to back up their hunches about who these groups are.
An unsupervised algorithm analyzes customer data like:
How often do they use the product
Age, location, and other demographics
How they interact with features
Purchase patterns
The system automatically discovers natural customer groups - maybe frequent power users, occasional bargain hunters, or new users still exploring. Once it identifies these segments, it can place new customers into the right group based on their behavior.
The key difference? Nobody tells the algorithm what groups to find - it discovers them naturally from the data patterns.
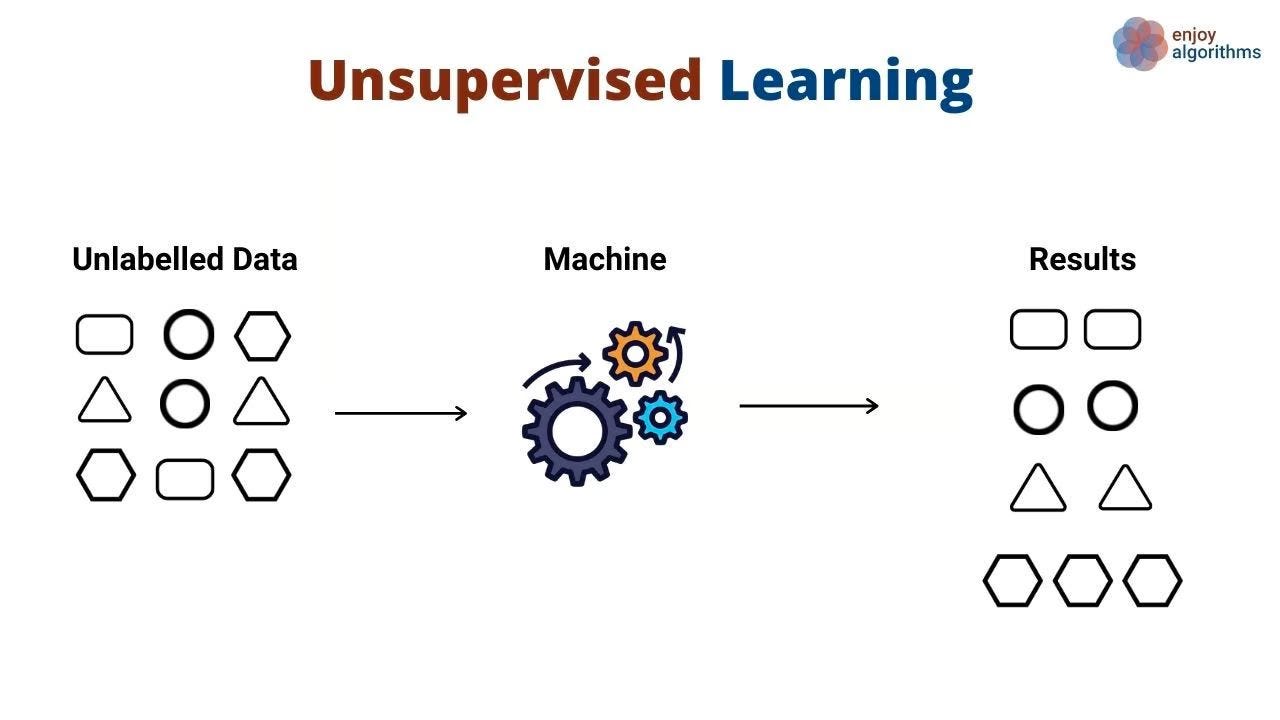
Unsupervised learning finds hidden patterns without being given examples of right and wrong answers. These algorithms explore data and automatically discover natural groupings.
Customer segmentation shows how this works. Companies know they have different customer types, but need data to prove it.
The algorithm studies customer information - usage frequency, demographics, feature interactions, and buying habits. It then discovers groups like power users, bargain hunters, or newcomers exploring the product.
Once trained, it can automatically sort new customers into these segments based on their behavior patterns.
The key point? The system finds these groups on its own - no one tells it what to look for.
Reinforcement Learning
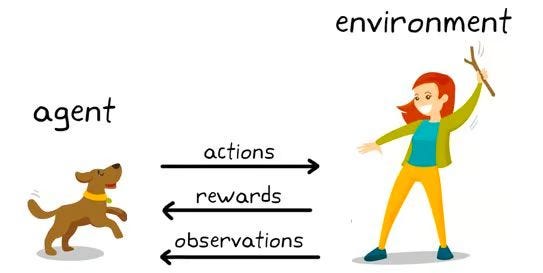
Reinforcement learning (RL) is a type of machine learning where an agent learns by getting rewards for good actions and penalties for bad ones. Though still largely in the research stage, RL has already powered systems that beat humans in games like Chess and Go.
Think of it like trial and error. The model (called an agent) interacts with an environment (like a chessboard), making decisions by playing different moves.
Each move earns a score, positive if it helps win, negative if it leads to a loss. Over time, the agent learns which actions bring the most rewards and repeats them. This is called exploitation. When it tries new moves to discover better outcomes, it’s in the exploration phase. Together, this process is known as the exploration-exploitation trade-off.
Self-Supervised Machine Learning
Self-supervised learning is a machine learning method that doesn't need labeled data. Instead, the model learns from raw, unlabeled inputs.
For example, a model is first given a bunch of unlabeled images. It groups them into clusters based on patterns it finds. Some images clearly fit into a group (high confidence), while others don’t.
In the next step, the model uses the confidently grouped images as labeled data to train a more accurate classifier, often more effective than using clustering alone.
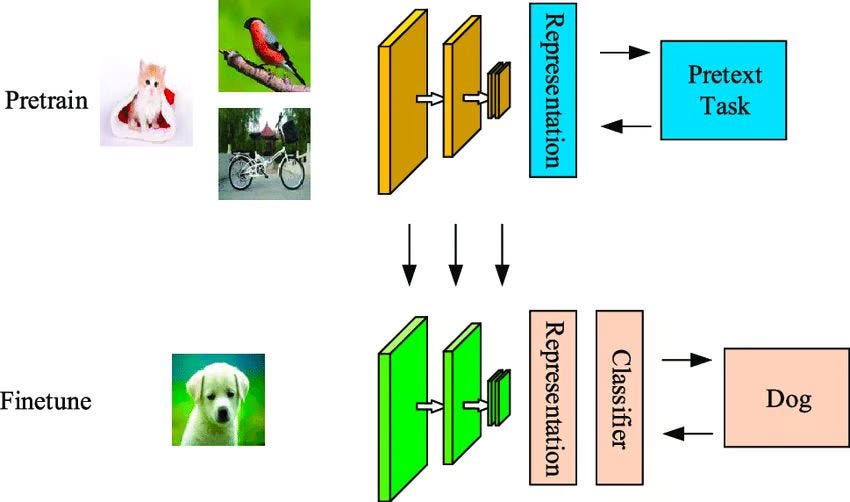
The key difference between self-supervised and supervised learning is that self-supervised models generate their own labels instead of relying on manually labeled data. While they can classify patterns, the output classes may not be linked to real-world objects, unlike in supervised learning, where labels are predefined and meaningful.
Top Most Popular Machine Learning Algorithms
Below, we’ve outlined some of the top machine learning algorithms and their most common use cases.
Top Supervised Machine Learning Algorithms
1. Linear Regression
A linear regression algorithm finds a straight-line relationship between input variables and a continuous output. It’s quick to train and easy to understand, making it great for explaining predictions. Common use cases include predicting customer lifetime value, housing prices, and stock trends
2. Decision Trees
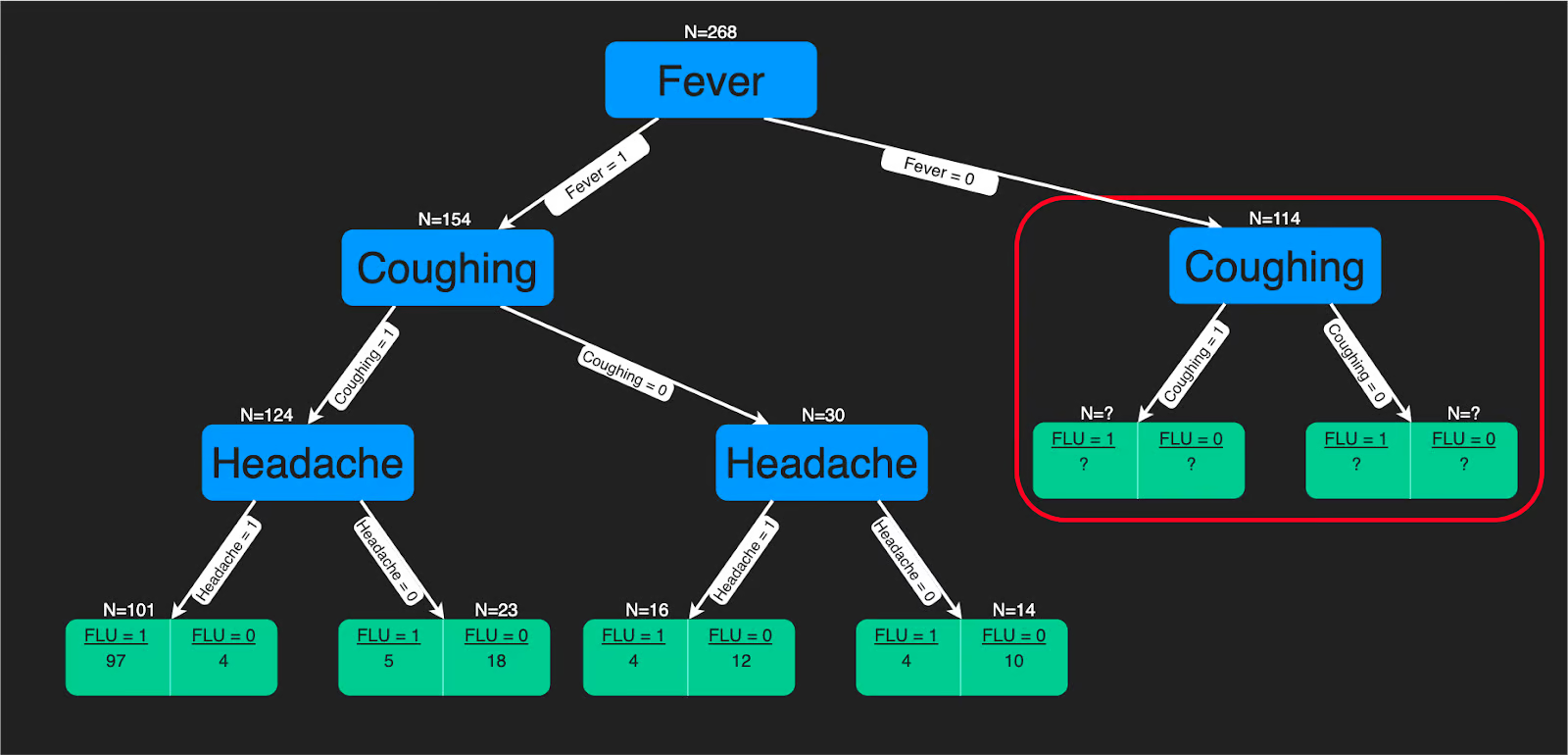
A decision tree is a model that uses a tree-like flow of decision rules based on input features to predict outcomes. It works well for both classification and regression tasks. Its simple, step-by-step logic makes it easy to understand, especially useful in fields like healthcare, where clear reasoning behind predictions is important.
3. Random Forest
Random Forest is a popular algorithm designed to fix the overfitting problem seen in decision trees. Overfitting happens when a model performs well on training data but poorly on new, unseen data.
Random Forest tackles this by creating multiple decision trees using random samples of the data. Each tree gives a prediction, and the final result is based on majority voting, making the model more accurate and reliable.
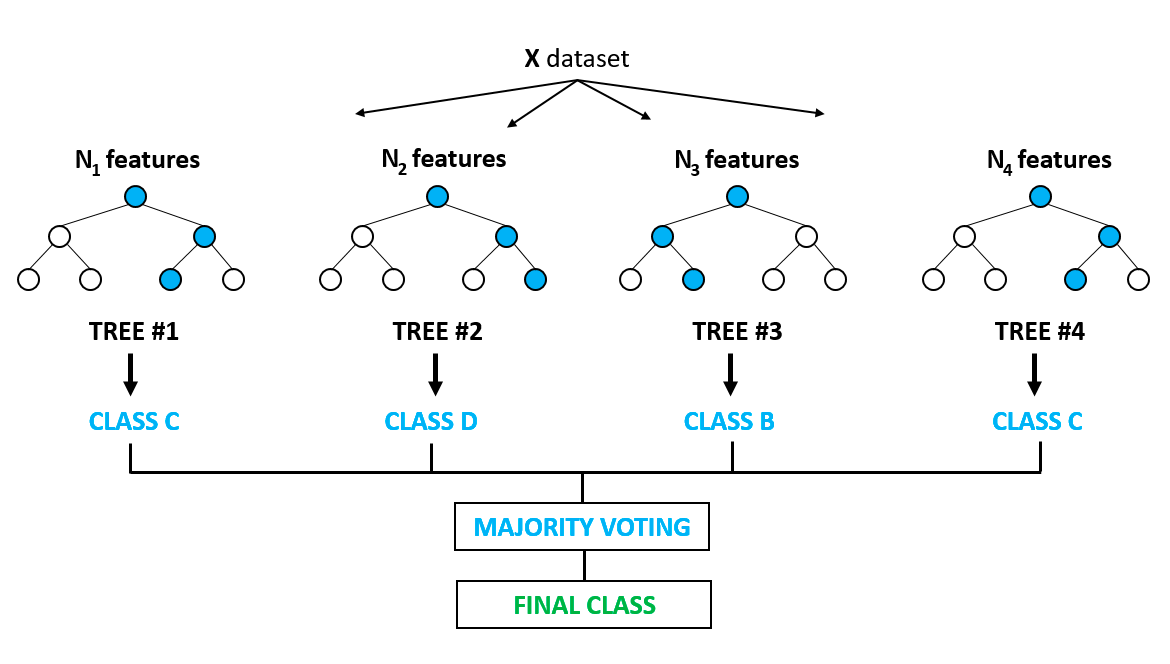
Random Forest works for both classification and regression tasks. It’s often used in areas like feature selection and disease detection. You can explore more by diving into tree-based models and ensemble methods, where multiple models are combined for better results.
4. Support Vector Machines
Support Vector Machines (SVM) are mainly used for classification tasks. They work by finding the best line or hyperplane—that separates different classes (like red and green dots) while maximizing the distance, or margin, between them for better accuracy.
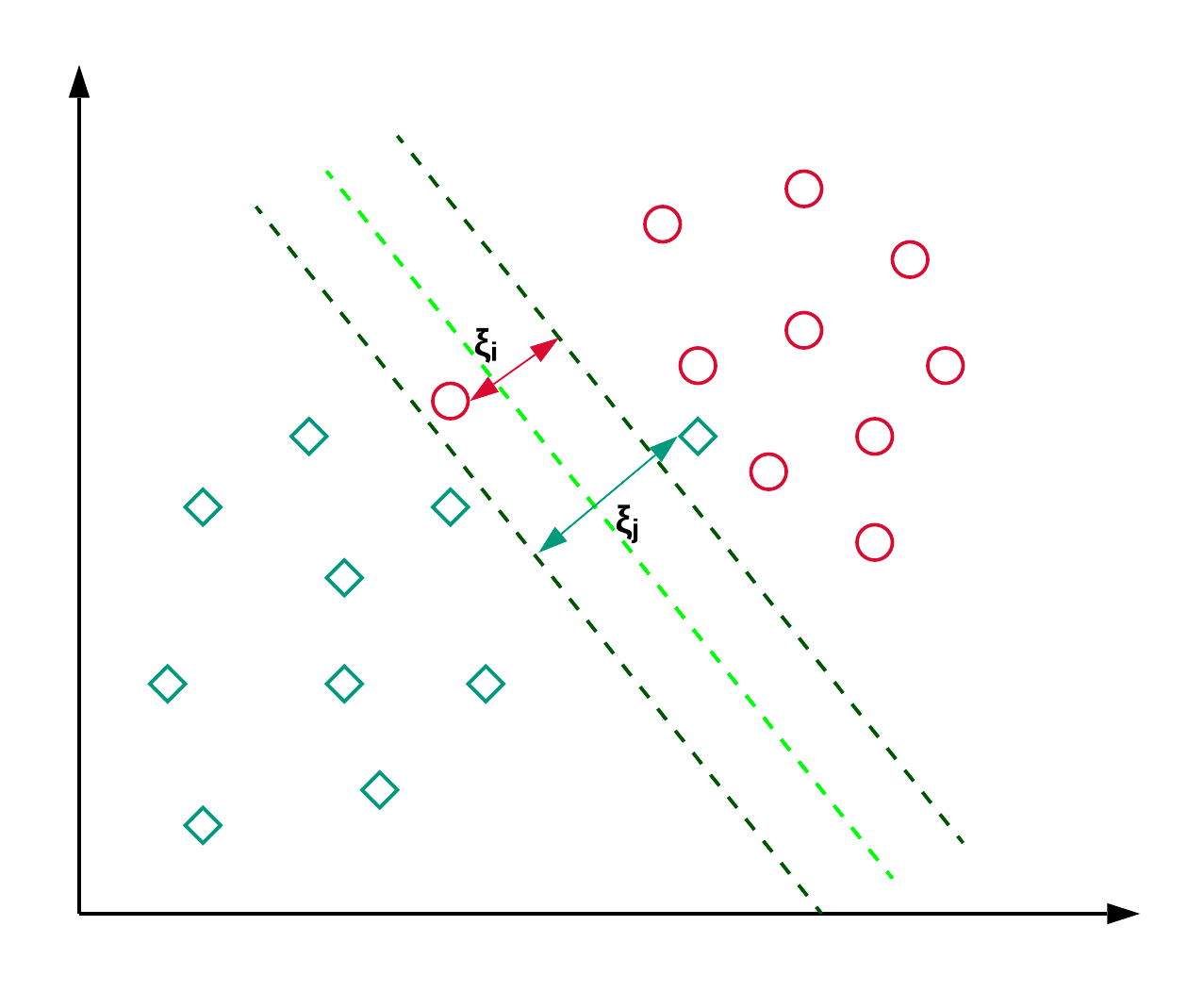
While SVM is mainly used for classification, it can also handle regression tasks. Common applications include classifying news articles and recognizing handwriting.
To dive deeper, explore different kernel tricks and check out the Python implementation using scikit-learn. You can also follow a tutorial to replicate the SVM in R for hands-on practice.
5. Gradient Boosting Regressor
Gradient Boosting Regression is an ensemble method that combines many weak models to create a strong predictor. It handles non-linear data well and deals effectively with multicollinearity.
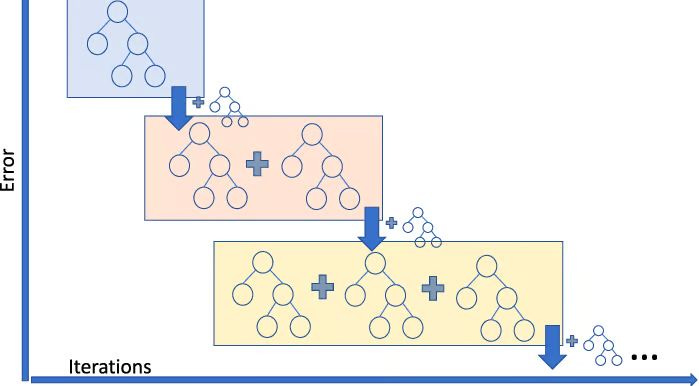
If you run a ride-sharing service and want to predict fare prices, a gradient boosting regressor can help make accurate predictions. To learn about the different types of gradient boosting methods, you can find many helpful video tutorials online.
Key Takeaways:
Machine learning helps computers learn patterns from data instead of following fixed rules, making them smarter and more adaptable.
It’s a core part of AI and powers many everyday technologies, like spam filters, self-driving cars, and voice assistants.
There are different types of machine learning:
Supervised learning: Learns from labeled examples to predict outcomes.
Unsupervised learning: Finds hidden patterns without labels.
Reinforcement learning: Learns by trial and error through rewards and penalties.
Self-supervised learning: Creates its own labels from raw data.
Popular algorithms include linear regression, decision trees, random forests, support vector machines, and gradient boosting — each suited to different tasks.
Whether you want to predict prices, classify images, or understand customer behavior, machine learning offers powerful tools that keep improving.
In short, machine learning is the engine behind many AI breakthroughs and a key skill to explore if you want to understand or build smart systems.