
AI Basics for Product Managers: Neural Networks, Transformers, and LLMs
The practical AI guide for PMs: Understanding the technology behind ChatGPT, Claude, and beyond.

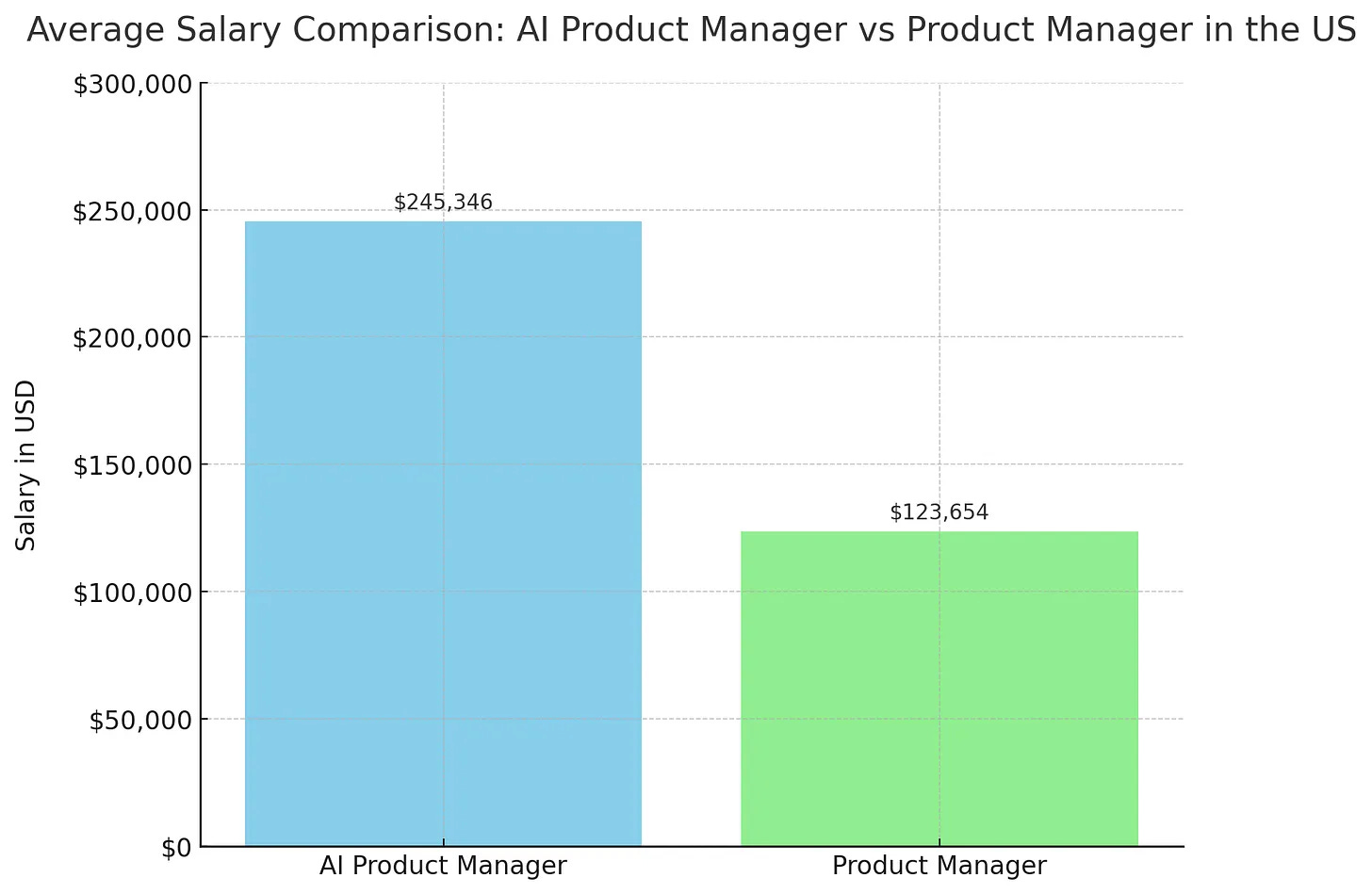
According to Glassdoor, the average salary for an AI Product Manager in the US is $245,346 per year, compared to $123,654 for a Product Manager.
On top of that, AI is quickly becoming a commodity, meaning you will need a basic understanding of it sooner rather than later in your career.
In this guide, we will walk you through the essential AI concepts every PM should understand:
The AI Landscape and Key Terms
How Neural Networks Work
How Transformers and LLMs Work
How Transformers Differ from the Human Brain
Key Takeaways
The AI Landscape and Key Terms
Artificial Intelligence (AI) is technology that allows computers to do things that usually require human thinking - like recognizing faces in photos, understanding speech, or solving problems.
Generative AI is the type of AI that's making the biggest impact today. Think of it as creative AI that can make brand-new content from scratch. Instead of just reading and organizing information that already exists, these AI systems can create original material.
You've probably already used some popular generative AI tools:
ChatGPT and similar chatbots, which write text, answer questions, and have conversations
DALL-E and Midjourney, that create images from text descriptions
GitHub Copilot, which writes computer code
Suno and Udio, who compose music
Runway and Sora that generate videos
These tools can produce all kinds of content: articles, emails, stories, artwork, logos, software programs, poems, marketing copy, educational materials, and much more. The AI learns patterns from millions of examples during training, then uses that knowledge to create something entirely new when you ask for it.

Let’s look at the AI landscape and the different machine learning methods that help Generative AI make sense of data and perform these tasks:
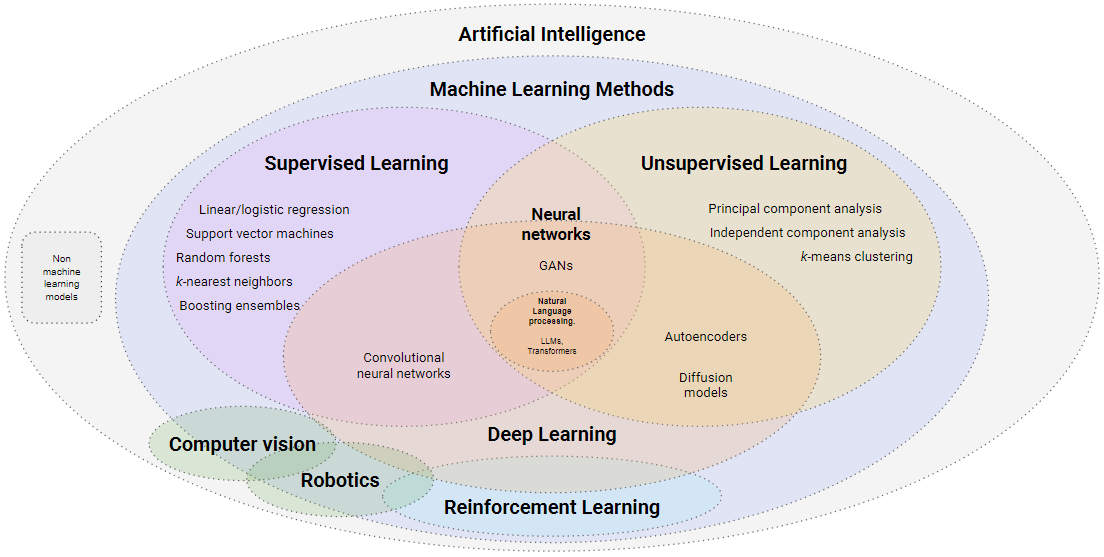
Here are four important types of machine learning every PM should know:
Supervised Learning: Models trained on labeled data (input + correct output) — essential for fine-tuning AI for specific product tasks
Unsupervised Learning: Models that find patterns in unlabeled data, like solving puzzles without reference images
Reinforcement Learning: Models that learn by trial and error with feedback rewards — think of AlphaGo mastering complex games
Deep Learning: A subset using multi-layered neural networks to handle complex pattern recognition
In this blogs, I'll focus primarily on Large Language Models (LLMs). Why? They're pre-trained on massive datasets, ready to deploy across various domains with minimal additional training, making them the most accessible and cost-effective AI technology for most product teams.
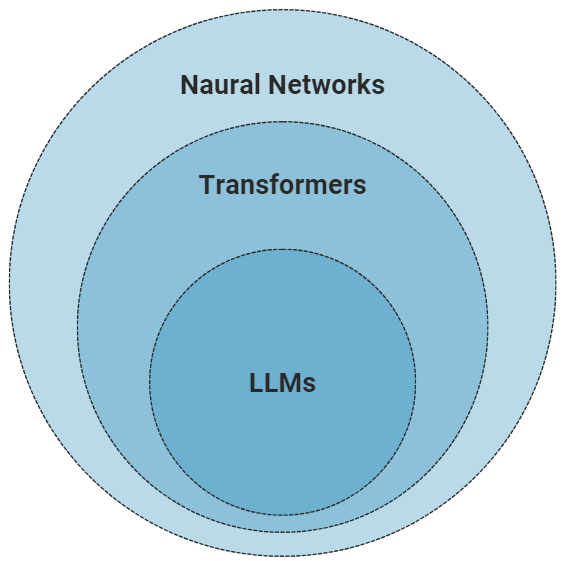
The key terms you need to know:
Neural Networks: Computational models inspired by the human brain's interconnected neurons
Transformers: A specific neural network architecture designed for processing sequential data (like text)
LLMs: Advanced models built on transformer architecture, trained on enormous datasets to understand and generate human-like text
Now, let's explore how these technologies actually work.
How Neural Networks Work
Neural networks are the foundation of modern AI, but what's happening under the hood?
I recommend experimenting with the TensorFlow Playground (https://playground.tensorflow.org/) to see neural networks in action. This free tool lets you visualize how these systems learn to recognize patterns:
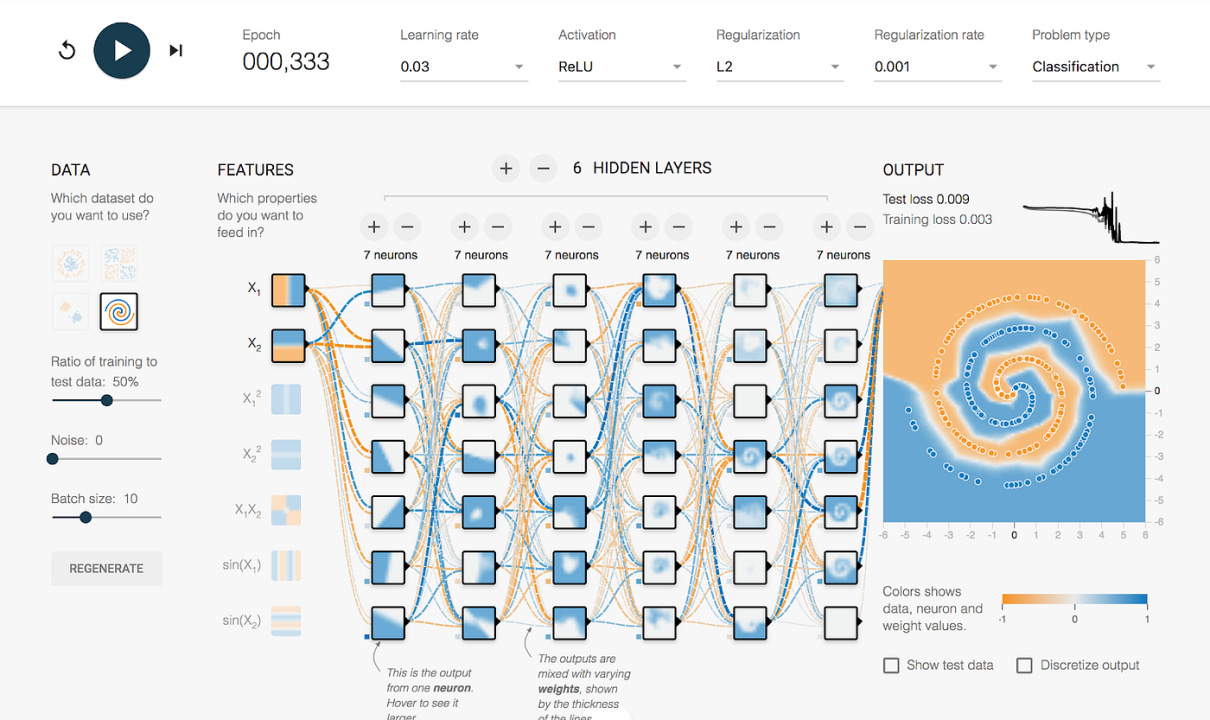
How a basic neural network processes information:
Input layer: Takes in raw data features (like X/Y coordinates of data points)
Hidden layers: Process and transform data through weighted connections
Output layer: Produces predictions or classifications
The magic happens through these key mechanisms:
Weights: Not all connections between neurons are equally important—weights determine their influence
Activation functions: (like Tanh) introduce non-linearity, allowing networks to learn complex patterns
Training epochs: The network processes batches of data, making predictions
Loss function: Measures how far predictions are from actual values
Backpropagation: Adjusts weights to minimize errors in future predictions
While powerful for many tasks, traditional neural networks struggle with sequential data, like understanding language. For instance, they might excel at classifying letters but fail at translating paragraphs between languages.
Why? Because language requires understanding context across long sequences of words, something that requires a different approach.
How Transformers and LLMs Work
Transformers revolutionized AI by effectively handling sequential data like text. Let's break down how they work using a simple example: translating "My name is Pawel" from English to French.
Step 1: Tokenization
First, the text is split into "tokens," but these aren't simply words. Tokens can be parts of words or even individual characters:
A screenshot from OpenAI’s tokenizer for GPT-4o, Akhil
A more complex default example presented by OpenAI:
A screenshot from OpenAI’s tokenizer for GPT-4o, Akhil
Step 2: Positional Encoding
Since transformers process all tokens simultaneously, they need a way to understand their order. This is achieved by encoding a position to each token:
#1 “My”
#2 “name”
#3 “is”
#4 “Akhil”
This ensures the model knows which token came first, second, and so on.
Step 3: Self-Attention Mechanism
This is the core strength of transformers. Each token "attends" to every other token in the sequence, giving them varying levels of importance based on how relevant they are.
While processing "is," it may give significant attention to "name" (to understand what is being named).
While processing "Akhil," it focuses on "name" and "is" (indicating that this is the name).
This creates a rich contextual understanding that previous architectures couldn't achieve.
Step 4: Multi-Head Attention
Transformers employ multiple "attention heads" to simultaneously capture various types of relationships. One head may concentrate on subject-verb connections, while another follows pronoun references.
Step 5: Feed-Forward Networks
After the attention mechanism, the data flows through feed-forward neural networks that perform additional transformations.
Step 6: Output Generation. For our translation example, the decoder component uses everything learned to generate "Je m'appelle Akhil" in French.
Large language models (LLMs) such as GPT-4, Claude, and Llama are essentially huge transformer-based models trained on vast amounts of text data. Their billions of parameters are fine-tuned to predict the next piece of text based on a given prompt—an ability that proves to be extremely effective for a wide range of language-related tasks.
How Transformers Differ from the Human Brain
While transformers achieve impressive results, they function very differently from the human brain:
Processing Approach
Human Brain: Processes information sequentially and recursively, gradually building understanding
Transformers: Handle all tokens simultaneously, using attention mechanisms to determine relationships
Learning Method
Human Brain: Learns continuously from experience with relatively few examples
Transformers: Limited by a fixed context window, lacking a true distinction between short- and long-term memory
Memory Structure
Human Brain: Has distinct working memory and long-term memory systems
Transformers: Limited by context window size; no true separation between short and long-term memory
Reasoning Capabilities
Human Brain: Excels at causal reasoning, abstraction, and applying knowledge to novel situations
Transformers: Can struggle with logical reasoning and often rely on statistical patterns rather than true understanding
Energy Efficiency
Human Brain: Extremely energy-efficient (runs on about 20 watts)
Transformers: Require significant computational resources and electricity
Interpretability
Human Brain: We can often explain human decision-making processes
Transformers: Often work as "black boxes" with limited explainability
These differences carry significant implications for products. For example, LLMs can produce answers that sound confident but are incorrect (hallucinations), have difficulty with complex reasoning, or overlook contextual subtleties that humans naturally understand. As a product manager, being aware of these limitations allows you to create AI features that enhance human abilities instead of trying to fully replace them.
Key Takeaways:
As AI becomes increasingly embedded in products across industries, here's what you should take away:
AI Skills Are Now Essential for Product Success: The salary gap between traditional and AI-focused Product Managers shows that companies highly value AI expertise. Even if you're not building AI-first products, understanding these technologies helps you spot opportunities to improve existing features and stay competitive.
Choose the Right Problems to Solve: AI excels at specific tasks like recognizing complex patterns, generating personalized content, automating repetitive work, and supporting human decision-making. Focus on use cases where AI's strengths align with real user needs rather than adding AI for its own sake.
Build Responsibly from Day One: Consider ethical implications early: training data can introduce bias, large models have environmental costs, users deserve transparency about AI-generated content, and data privacy must be protected. These aren't afterthoughts—they're core product decisions.
Start Simple, Scale Smart: You don't need to build the next ChatGPT. Begin by integrating existing AI APIs into specific features, creating small prototypes to test concepts, and designing for human-AI collaboration where each contributes their strengths. The most successful AI products enhance human capabilities rather than replace them.
AI literacy is quickly becoming as fundamental to product management as understanding user research or analytics. By mastering these concepts, you'll be better positioned to lead products that thoughtfully integrate AI capabilities, creating more value for your users and organization.